
SQL Window function
Dissecting the window function
A window function is a powerful feature of SQL that allows users to perform calculations and analysis on the subset of rows within a query. The window function performs calculations on the data without aggregating current rows
Window functions compute the result based on a sliding window frame. A window frame is a set of rows that are related to the current row. The relation is that all the rows have the same value for all terms of the PARTITION BY clause in the window definition. The window frame is evaluated separately within each partition. Partition By clause subdivides rows into multiple groups.


Syntax
SELECT <column list>,
<window_function> OVER (
PARTITION BY <>
ORDER BY <>
<window_frame>
) window_alias
FROM <table_name>ORSELECT <column list> OVER <window_definition_name>
FROM <table_name>
WINDOW window_definition_name AS (
PARTITION BY <>
ORDER BY <>
<window_frame>
)
Example
SELECT city, month,
SUM(amount) OVER (
PARTITION BY city
ORDER BY month
RANGE UNBOUNDED PRECEDING
) as total_sale
FROM Sales;ORSELECT city, month, SUM(amount) OVER window_definition_name
FROM Sales
WINDOW window_definition_name AS (
PARTITION BY city
ORDER BY month
RANGE UNBOUNDED PRECEDING
)
The above window function is understood as following:

Note
- PARTITION BY clause optional, if we do not specify PARTITION BY clause, then the function treats all rows as a single partition
- FRAME (ROWS | RANGE) clause further defines a subset of the current partition.
Position of Window function in overall Logical order of operators:
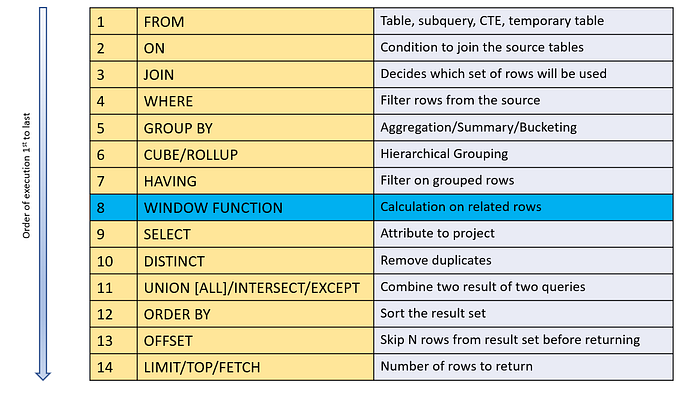
So from above, we know that the window function is applied just before the select part runs. By this time the database server has completed all of the steps necessary to evaluate a query, including joining, filtering, grouping, and sorting, and the result set is complete and ready to be returned to the caller. The window function is applied to this result set while it is still held in memory.
Unlike the aggregate function, the window function does not collapse the rows.
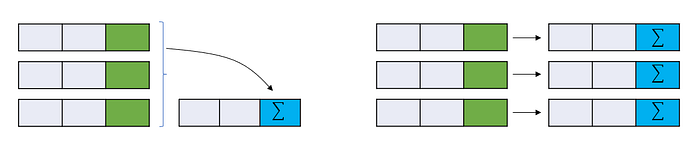
In window specification we can provide three different frame clauses:
ROWS BETWEEN— rows at a distance N from current rows in partition
RANGE —rows based on their value compared to the current row.
GROUPS — counts all groups of tied rows within the window (In Postgres)
[UNBOUNDED] PRECEDING | CURRENT ROW | [UNBOUNDED] FOLLOWING
We can use the following window functions:
Aggregate Function
COUNT, MAX, MIN, SUM, AVG
Ranking Functions
ROW_NUMBER, RANK, DENSE_RANK
Distribution Functions
PERCENT_RANK, CUME_DIST, NTILE
Positional Functions
LEAD, LAG, NTH_VALUE, FIRST_VALUE, LAST_VALUE
The syntax for lead/lag function.
LEAD | LAG ( expression, offset, deafult_value) OVER
These two functions are useful while doing YoY, and QoQ comparisons.
Analytic Functions
NTILE
Note: We can’t use the window function in the where clause to filter data.
Problem
185. Department Top Three Salaries
Employee Table
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| id | int |
| name | varchar |
| salary | int |
| departmentId | int |
+--------------+---------+Department Table
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| name | varchar |
+-------------+---------+A company’s executives are interested in seeing who earns the most money in each of the company’s departments. A high earner in a department is an employee who has a salary in the top three unique salaries for that department. Write an SQL query to find the employees who are high earners in each of the departments. Return the result table in any order.
Example
Input:
Employee table:
+----+-------+--------+--------------+
| id | name | salary | departmentId |
+----+-------+--------+--------------+
| 1 | Joe | 85000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
| 5 | Janet | 69000 | 1 |
| 6 | Randy | 85000 | 1 |
| 7 | Will | 70000 | 1 |
+----+-------+--------+--------------+
Department table:
+----+-------+
| id | name |
+----+-------+
| 1 | IT |
| 2 | Sales |
+----+-------+
Output:
+------------+----------+--------+
| Department | Employee | Salary |
+------------+----------+--------+
| IT | Max | 90000 |
| IT | Joe | 85000 |
| IT | Randy | 85000 |
| IT | Will | 70000 |
| Sales | Henry | 80000 |
| Sales | Sam | 60000 |
+------------+----------+--------+
Explanation:
In the IT department:
- Max earns the highest unique salary
- Both Randy and Joe earn the second-highest unique salary
- Will earns the third-highest unique salary
In the Sales department:
- Henry earns the highest salary
- Sam earns the second-highest salary
- There is no third-highest salary as there are only two employeesSolution:
We first assign a rank to all salaries within the department. We achieve this by using the window function as below:
SELECT
departmentId, name, salary,
DENSE_RANK() OVER (PARTITION BY departmentId ORDER BY Salary desc) as r
FROM EmployeeThe output of the above query is as follows:
+--------------+-------+--------+----+
| departmentId | name | salary | r |
+--------------+-------+--------+----+
| 1 | Max | 90000 | 1 |
| 1 | Joe | 85000 | 2 |
| 1 | Randy | 60000 | 2 |
| 1 | Will | 90000 | 3 |
| 1 | Janet | 69000 | 4 |
| 2 | Henry | 85000 | 1 |
| 2 | Sam | 70000 | 2 |
+--------------+-------+--------+----+Once we have this result we just filter out the rows which have a rank < 4 (1, 2, 3).
WITH ranked_salary_for_each_dept AS (
SELECT departmentId, name, salary, DENSE_RANK() OVER (PARTITION BY departmentId ORDER BY Salary desc) as r
FROM Employee
)
select d.Name as "Department", a.Name as "Employee", a.Salary as "Salary"
from ranked_salary_for_each_dept a
join Department d on a.departmentId = d.Id
where a.r < 4Happy Windowing!!

