
Hive data organization — Partitioning & Clustering
Data organization impacts the query performance of any data warehouse system. Hive is no exception to that. This blog aims at discussing Partitioning, Clustering(bucketing) and consideration around them.
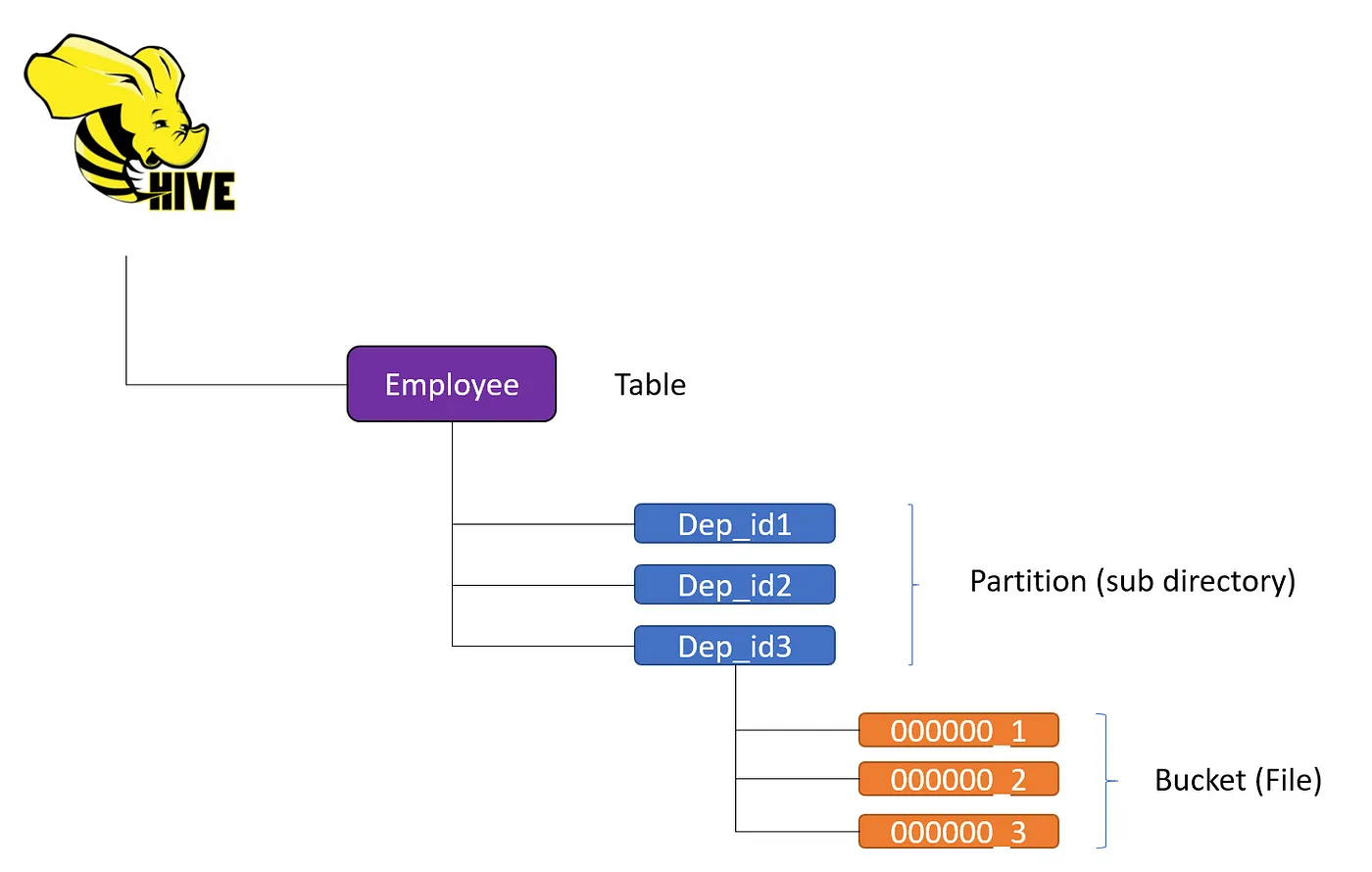
The above diagram depicts the hierarchy of the files handled by Hive for a table which is partitioned and bucketed. Tables and partitions are directory or sub-directory, while buckets are actual files. In case we do not apply those we will have single file under Employee directory. If we apply bucketing and no partitioning then we will have N number of files named as 000000_1 …… 00000_N. In case of partitioning we will have directories equal to the cardinality of the column on which we partition the data. If we partition on multiple column then the number of subdirectories become cardinality of column 1 * cardinality of column 2. If we apply both partitioning and bucketing then we will end up with N(number of buckets) files under the partition sub directory.
I mentioned these things as these help in deciding on how to efficiently use these concepts to optimize query execution times.
Partitioning
PARTITIONED BY (Dept_id INT)
Partitioning is a way of distributing the data load horizontally into more manageable chunks/directories and sub-directories. This allows us to organize data in more logical function. In the above diagram we created partitions on Dept_id. Lets say we have 3 departments with even distribution of employees. In that case we will end up with three sub-directories. That will be based on the Dept_id. This will help us on skipping the data from departments we are not interacting with in the query. This helps in improving query performance if we are dealing with lot of queries having Dept_id in the predicate (WHERE clause). The data of the partition column(s) are not stored in the files. It’s intuitive as well since we don’t add the column, on which we do partition, in the create table expression.
Dynamic and Static Partitioning
Partition management in Hive can be done in two ways. Static (user manager) or Dynamic (managed by hive).
In Static Partitioning we need to specify the partition in which we want to load the data. Also partition can be added using ADD PARTITION operation.
In Dynamic Partitioning partitions get created automatically while data load operation happens based on the value of the column on which the partition is defined.
To enable dynamic partitioning we need to use set below hive configuration
SET hive.exec.dynamic.partition=true
SET hive.exec.dynamic.partition.mode=nonstrict
If we don’t set the second option then we cant create dynamic partition unless we have at least one static partition.
Clustering
CLUSTERED BY (Emp_id) INTO 3
Bucketing or clustering is a way of distributing the data load into a user supplied set of buckets by calculating the hash of the key and taking modulo with the number of buckets/clusters. In case we have clustered the table based on employee id. Emp_id which gives the same value after hash and modulo will go in the same file.
SET hive.enforce.bucketing=true
Let say we have 9 GB of employee data and each department has 3Gb worth of data (assuming even distribution of employee across departments). In that case we will have roughly 9 files with (9Gb)/(no of department(3) * no of clusters(3)) = 1Gb/file storing employee data.
Bucketing is suitable technique for sampling and join optimization. In star schema facts table bucketing is good place to start with.
Bucketing can be done independent of partitioning. In that case files will be under table’s directory.
Considerations
- Partitioning scheme, in use, should reflect common filtering.
2. Partitioning column should have very low cardinality. Higher cardinality will create too many partitions. Which will create large number of files and directories. This will add overhead on hive metastore as it needs to keep metadata of partition.
SET hive.partition.pruning=strict
3. This ensures that if someone issues query against a partitioned table without predicate it will throw compilation error.
4. Handle Dynamic partitioning with care as it can lead to a high number of partitions.
5. Ensure to create buckets in such a way that each file is not too small(less than HDFS block size). Good threshold should be around 1GB.
6. Although we can do clustering based on multiple columns, it should be used with due diligence.
7. Bucketing is suitable for attribute with high cardinality. Generally choose attributes which are frequently used in Group By or Order by clause
8. No of buckets can’t be changed after table creation.
9. (file size / number of buckets) > HDFS block size.
Hope it was useful.
References:
https://journalofbigdata.springeropen.com/articles/10.1186/s40537-019-0196-1
