
Data Processing Architectures
Lambda & Kappa
Modern data processing platforms need to process real-time streaming events in addition to more traditional data pipelines. Deciding on the right architecture, Lambda or Kappa is an important step in the direction of a good platform strategy.
Design goals for Data processing Architectures:
- Read consistent data
- Read incrementally from large tables/datasets
- Rollback
- Capability to replay historical events
- Handling of the late arrival of data
Let us see the two architectures.
Lambda
Lambda architecture is a hybrid (stream & batch) approach to processing Big Data. The lambda architecture itself is composed of 3 layers:
- Batch Layer — Process data at regular intervals
- Stream Layer — process data not included in the last batch window
- Serving Layer — unified layer to get data from batch and stream
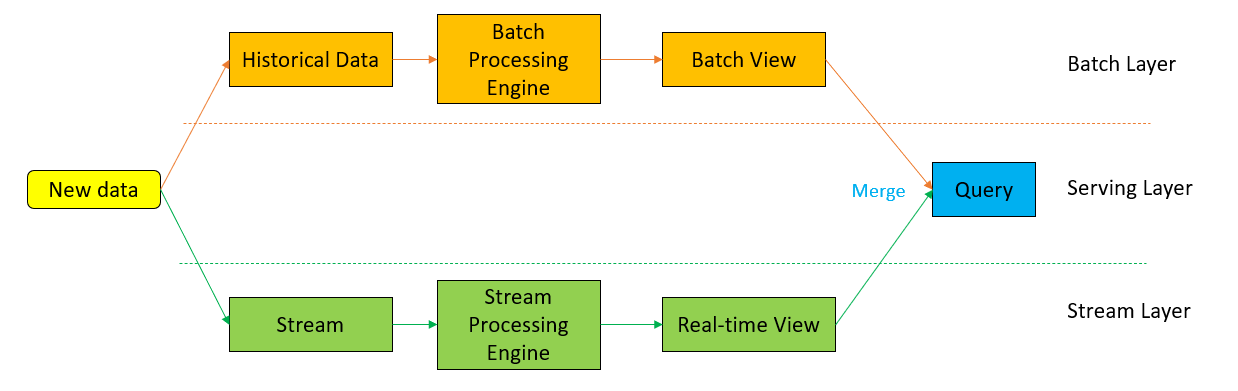
Pros
- The batch layer of Lambda architecture is fault tolerant as it uses distributed storage.
- It gives a balance between speed and reliability.
- Since stream and batch are separate we can scale them individually.
Cons
- Coding overhead.
- It re-processes data from the stream in the next batch cycle.
- Difficult to migrate.
Kappa
Kappa Architecture is considered a simpler version of Lambda Architecture.
In Kappa, Everything is a stream.
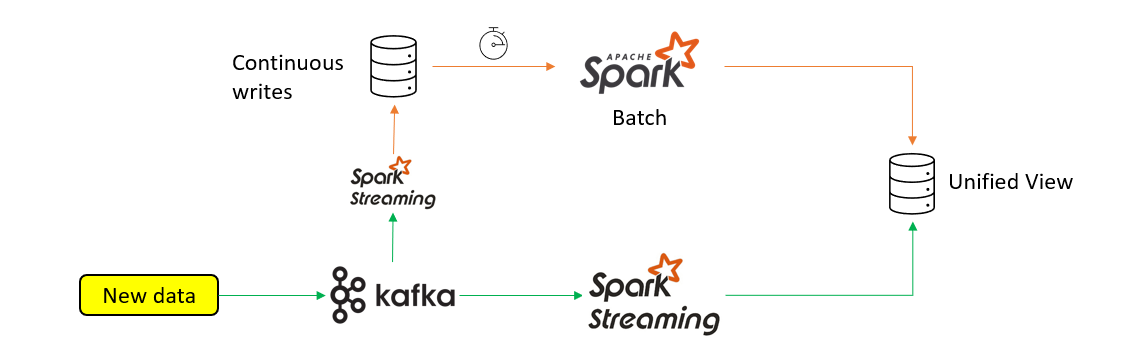
Kappa Architecture performs both real-time and batch processing with a single technology stack (streaming). In this design incoming series of data is first stored in a messaging engine like Apache Kafka (similar tools can also be used like Pulsar, Kinesis, and EventHub). A stream processing engine will read the data and transform it into the desired format, and store it in an analytics database for end users to query.


In Kappa architecture, Reads and writes are decoupled. The read & write model is just a projection.
Pros
- Less code overhead, as a single processing stack is used
- No duplicate processing of events
- Queries only need to look at a single view, no need to create a unified view.
- Kappa architecture is implemented at companies like Twitter, Uber, Netflix, Disney, and Shopify. So there is good documentation and practical experience to start with.
Cons
- Need complex setup to handle duplicate events, cross-referencing events, or maintaining order.
- Difficult backfilling, but with new table formats like Iceberg, it is straightforward.
- Need to implement a global watermark.
- Usual metadata solutions cannot be used for governance.
Kappa is not a replacement for Lambda, it is an alternative for cases where the active performance of the batch layer is not necessary for meeting the standard quality of service. In most cases, you will start off with lambda layers and spin off some use cases best suited to Kappa architecture.

