Amit Singh RathoreinDev GeniusEvolution of pod’s privilege in EKSHost role → Proxy roles →IRSA → Pod Identity2d ago2d ago
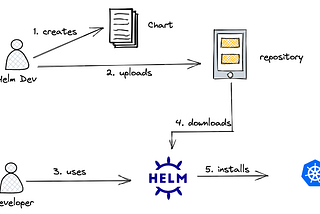
Amit Singh RathoreinDev GeniusData Platform on K8s with helmList of helm charts to build a data engineering platform4d ago4d ago
Amit Singh RathoreinDev GeniusApache Kafka Interview QuestionsList of some questions to go through to understand Kafka5d ago5d ago
Amit Singh RathoreinDev GeniusAWS Lambda Interview Series — IIThe second installment of the series on Lambda interview questions.6d ago6d ago
Amit Singh RathoreinDev GeniusAWS Lambda Interview Series — ISome common question on Lambda6d ago6d ago